In 1957, Nobel laureate microbiologist Joshua Lederberg and biostatician J. B. S. Haldane sat down together imagined what would happened if the USSR decided to explode a nuclear weapon on the moon.
The Cold War was on, Sputnik had recently been launched, and the 40th anniversary of the Bolshevik Revolution was coming up – a good time for an awe-inspiring political statement. Maybe they read a recent United Press article about the rumored USSR plans. Nuking the moon would make a powerful political statement on earth, but the radiation and disruption could permanently harm scientific research on the moon.
What Lederberg and Haldane did not know was that they were onto something – by the next year, the USSR really investigated the possibility of dropping a nuke on the moon. They called it “Project E-4,” one of a series of possible lunar missions.
What Lederberg and Haldane definitely did not know was that that same next year, 1958, the US would also study the idea of nuking the moon. They called it “Project A119” and the Air Force commissioned research on it from Leonard Reiffel, a regular military collaborator and physicist at the University of Illinois. He worked with several other scientists, including a then-graduate-student named Carl Sagan.
“Why would anyone think it was a good idea to nuke the moon?”
That’s a great question. Most of us go about our lives comforted by the thought “I would never drop a nuclear weapon on the moon.” The truth is that given a lot of power, a nuclear weapon, and a lot of extremely specific circumstances, we too might find ourselves thinking “I should nuke the moon.”
During the Cold War, dropping a nuclear weapon on the moon would show that you had the rocketry needed to aim a nuclear weapon precisely at long distances. It would show off your spacefaring capability. A visible show could reassure your own side and frighten your enemies.
It could do the same things for public opinion that putting a man on the moon ultimately did. But it’s easier and cheaper:
- As of the dawn of ICBMs you already have long-distance rockets designed to hold nuclear weapons
- Nuclear weapons do not require “breathable atmosphere” or “water”
- You do not have to bring the nuclear weapon safely back from the moon.
There’s not a lot of English-language information online about the USSR E-4 program to nuke the moon. The main reason they cite is wanting to prove that USSR rockets could hit the moon.3 The nuclear weapon attached wasn’t even the main point! That explosion would just be the convenient visual proof.
They probably had more reasons, or at least more nuance to that one reason – again, there’s not a lot of information accessible to me.* We have more information on the US plan, which was declassified in 1990, and probably some of the motivations for the US plan were also considered by the USSR for theirs.
- Military
- Scare USSR
- Demonstrate nuclear deterrent1
- Results would be educational for doing space warfare in the future2
- Political
- Reassure US people of US space capabilities (which were in doubt after the USSR launched Sputnik)
- More specifically, that we have a nuclear deterrent1
- “A demonstration of advanced technological capability”2
- Reassure US people of US space capabilities (which were in doubt after the USSR launched Sputnik)
- Scientific (they were going to send up batteries of instruments somewhat before the nuking, stationed at distances from the nuke site)
- Determine thermal conductivity from measuring rate of cooling (post-nuking) (especially of below-dust moon material)
- Understand moon seismology better via via seismograph-type readings from various points at distance from the explosion
- And especially get some sense of the physical properties of the core of the moon2

In the USSR, Aleksandr Zheleznyakov, a Russian rocket engineer, explained some reasons the USSR did not go forward with their project:
- Nuke might miss the moon
- and fall back to earth, where it would detonate, because of the planned design which would explode upon impact
- in the USSR
- in the non-USSR (causing international incident)
- and circle sadly around the sun forever
- and fall back to earth, where it would detonate, because of the planned design which would explode upon impact
- You would have to tell foreign observatories to watch the moon at a specific time and place
- And… they didn’t know how to diplomatically do that? Or how to contact them?
The US has less information. While they were not necessarily using the same sea-mine style detonation system that the planned USSR moon-nuke would have3, they were still concerned about a failed launch resulting in not just a loose rocket but a loose nuclear weapon crashing to earth.2
(I mean, not that that’s never happened before.)
Even in his commissioned report exploring the feasibility, Leonard Reiffel and his team clearly did not want to nuke the moon. They outline several reasons this would be bad news for science:
- Environmental disturbances
- Permanently disrupting possible organisms and ecosystems
- In maybe the strongest language in the piece, they describe this as “an unparalleled scientific disaster”
- Radiological contamination
- There are some interesting things to be done with detecting subtle moon radiation – effects of cosmic rays hitting it, detecting a magnetosphere, various things like the age of the moon. Nuking the moon would easily spread radiation all over it. It wouldn’t ruin our ability to study this, especially if we had some baseline instrument readings up there first, but it wouldn’t help either.
- To achieve the scientific objective of understanding moon seismology, we could also just put detectors on the moon and wait. If we needed more force, we could just hit the moon with rockets, or wait for meteor impacts.
I would also like to posit that nuking the moon is kind of an “are we the baddies?” moment, and maybe someone realized that somewhere in there.

Afterwards
That afternoon they imagined the USSR nuking the moon, Lederberg and Haldane ran the numbers and guessed that a nuclear explosion on the moon would be visible from earth. So the USSR’s incentive was there. They couldn’t do much about that but they figured this would be politically feasible, and that this was frightening because such a contamination would disrupt and scatter debris all over the unexplored surface of the moon – the closest and richest site for space research, a whole mini-planet of celestial material that had not passed through the destructive gauntlet of earth’s atmosphere (as meteors do, the force of reentry blasting away temperature-sensitive and delicate structures).
Lederberg couldn’t stop the USSR from nuking the moon. But early in the space age, he began lobbying for avoiding contaminating outer space. He pushed for a research-based approach and international cooperation, back when cooperating with the USSR was not generally on the table. His interest and scientific clout lead colleagues to take this seriously. We still do this – we still sanitize outgoing spacecraft so that hardy Earth organisms will (hopefully) not colonize other planets.
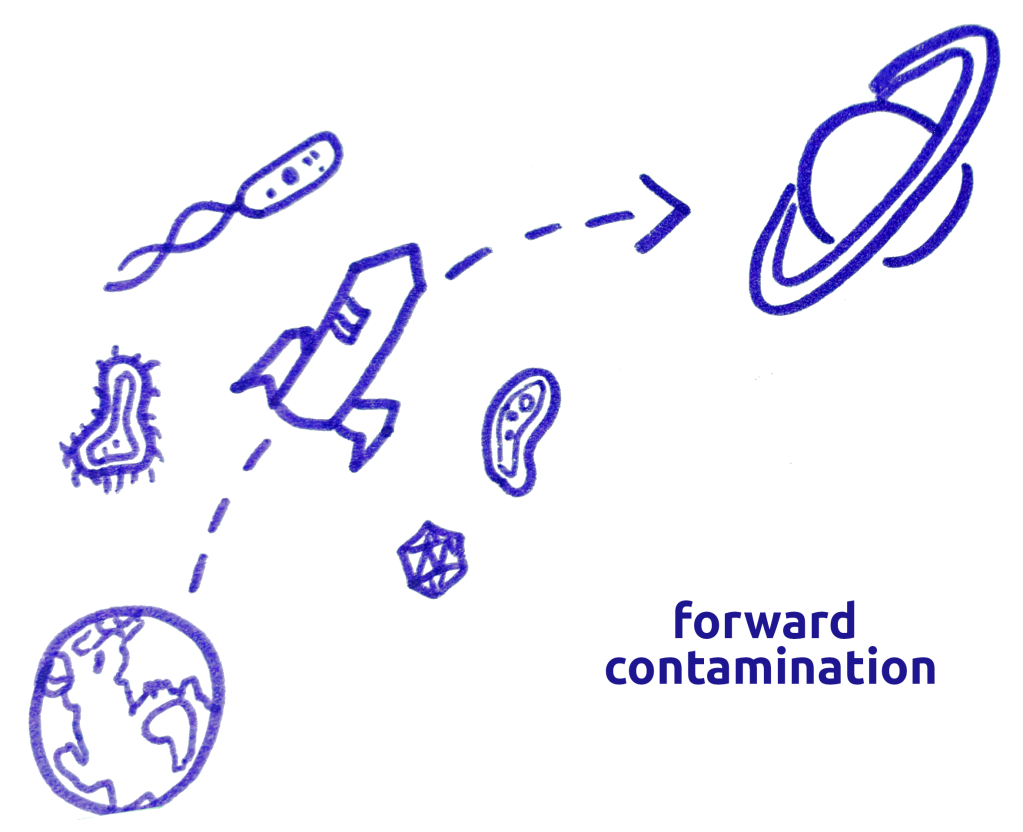
Lederberg then took some further steps and realized that if there was a chance Earth organisms could disrupt or colonize Moon life, there was a smaller but deadlier chance that Moon organisms could disrupt or colonize Earth life.
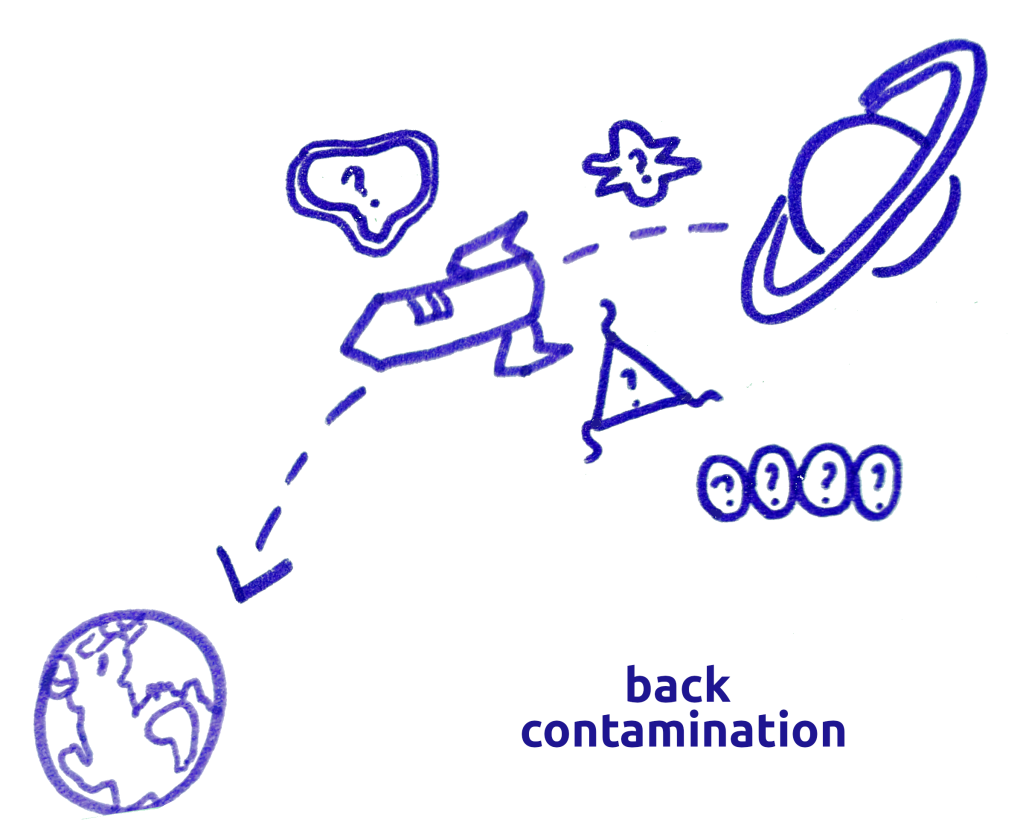
He realized that in returning space material to earth, we should proceed very, very cautiously until we can prove that it is lifeless. His efforts were instrumental in causing the Apollo program to have an extensive biosecurity and contamination-reduction program. That program is its own absolutely fascinating story.
Early on, a promising young astrophysicist joined Lederberg in A) pioneering the field of astrobiology and B) raising awareness of space contamination – former A119 contributor and future space advocate Carl Sagan.
Here’s what I think happened: a PhD student fascinated with space works on secret project that he’d worked on with his PhD advisor on nuking the moon. He assists with this work, finding it plausible, and is horrified for the future of space research. Stumbling out of this secret program, he learns about a renowned scientist (Joshua Lederberg) calling loudly for care in space contamination.
Sagan perhaps learns, upon further interactions, that Lederberg came to this fear after considering the idea that our enemies would detonate a nuclear bomb on the moon as a political show.
Why, yes, Sagan thinks. What if someone were foolish enough to detonate a nuclear bomb on the moon? What absolute madmen would do that? Imagine that. Well, it would be terrible for space research. Let’s try and stop anybody from ever doing that that.

And if it helps, he made it! Over fifty years later and nobody thinks about nuking the moon very often anymore. Good job, Sagan.
This is just speculation. But I think it’s plausible.
If you like my work and want to help me out, consider checking out my Patreon! Thanks.
References
* We have, like, the personal website of a USSR rocket scientist – reference 3 below – which is pretty good.
But then we also have an interview that might have been done by journalist Adam Tanner with Russian rocket scientist Boris Chertok, and published by Reuters in 1999. I found this on an archived page from the Independent Online, a paper that syndicated with Reuters, where it was uploaded in 2012. I emailed Reuters and they did not have the interview in their archives, but they did have a photograph taken of Chertok from that day, so I’m wondering if they published the article but simply didn’t properly archive it later, and if the Independent Online is the syndicated publication that digitized this piece. (And then later deleted it, since only the Internet Archived copy exists now.) I sent a message to who I believe is the same Adam Tanner who would have done this interviewee, but haven’t gotten a response. If you have any way of verifying this piece, please reach out.
1: Associated Press, as found in the LA Times Archive, “U.S. Weighed A-Blast on Moon in 1950s.” 2008 May 18. https://www.latimes.com/archives/la-xpm-2000-may-18-mn-31395-story.html
2. Project A119, “A Study of Lunar Research Flights”, 1959 June 15. Declassified report: https://archive.org/details/DTIC_AD0425380
This is an extraordinary piece to read. I don’t think I’ve ever read a report where a scientist so earnestly explores a proposal and tries to solve various technical questions around it, and clearly does not want the proposal to go forward. For instance:

3. Aleksandr Zheleznyakov, translated by Sven Grahm, updated 1999 or so. “The E-4 project – exploding a nuclear bomb on the Moon.” http://www.svengrahn.pp.se/histind/E3/E3orig.htm