Several Apple customers recently reported being targeted in elaborate phishing attacks that involve what appears to be a bug in Apple’s password reset feature. In this scenario, a target’s Apple devices are forced to display dozens of system-level prompts that prevent the devices from being used until the recipient responds “Allow” or “Don’t Allow” to each prompt. Assuming the user manages not to fat-finger the wrong button on the umpteenth password reset request, the scammers will then call the victim while spoofing Apple support in the caller ID, saying the user’s account is under attack and that Apple support needs to “verify” a one-time code.
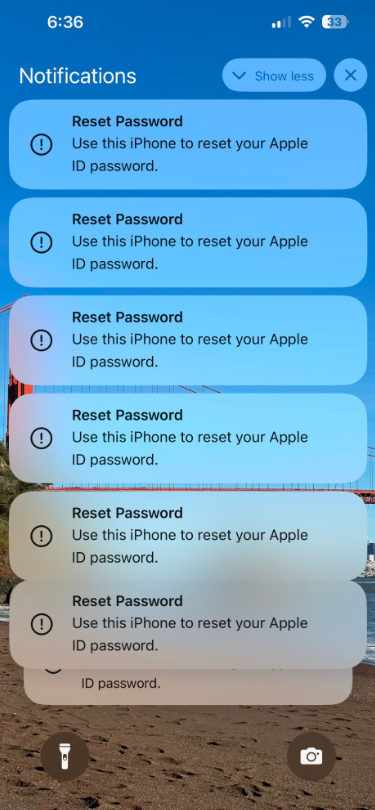
Some of the many notifications Patel says he received from Apple all at once.
Parth Patel is an entrepreneur who is trying to build a startup in the conversational AI space. On March 23, Patel documented on Twitter/X a recent phishing campaign targeting him that involved what’s known as a “push bombing” or “MFA fatigue” attack, wherein the phishers abuse a feature or weakness of a multi-factor authentication (MFA) system in a way that inundates the target’s device(s) with alerts to approve a password change or login.
“All of my devices started blowing up, my watch, laptop and phone,” Patel told KrebsOnSecurity. “It was like this system notification from Apple to approve [a reset of the account password], but I couldn’t do anything else with my phone. I had to go through and decline like 100-plus notifications.”
Some people confronted with such a deluge may eventually click “Allow” to the incessant password reset prompts — just so they can use their phone again. Others may inadvertently approve one of these prompts, which will also appear on a user’s Apple watch if they have one.
But the attackers in this campaign had an ace up their sleeves: Patel said after denying all of the password reset prompts from Apple, he received a call on his iPhone that said it was from Apple Support (the number displayed was 1-800-275-2273, Apple’s real customer support line).
“I pick up the phone and I’m super suspicious,” Patel recalled. “So I ask them if they can verify some information about me, and after hearing some aggressive typing on his end he gives me all this information about me and it’s totally accurate.”
All of it, that is, except his real name. Patel said when he asked the fake Apple support rep to validate the name they had on file for the Apple account, the caller gave a name that was not his but rather one that Patel has only seen in background reports about him that are for sale at a people-search website called PeopleDataLabs.
Patel said he has worked fairly hard to remove his information from multiple people-search websites, and he found PeopleDataLabs uniquely and consistently listed this inaccurate name as an alias on his consumer profile.
“For some reason, PeopleDataLabs has three profiles that come up when you search for my info, and two of them are mine but one is an elementary school teacher from the midwest,” Patel said. “I asked them to verify my name and they said Anthony.”
Patel said the goal of the voice phishers is to trigger an Apple ID reset code to be sent to the user’s device, which is a text message that includes a one-time password. If the user supplies that one-time code, the attackers can then reset the password on the account and lock the user out. They can also then remotely wipe all of the user’s Apple devices.
THE PHONE NUMBER IS KEY
Chris is a cryptocurrency hedge fund owner who asked that only his first name be used so as not to paint a bigger target on himself. Chris told KrebsOnSecurity he experienced a remarkably similar phishing attempt in late February.
“The first alert I got I hit ‘Don’t Allow’, but then right after that I got like 30 more notifications in a row,” Chris said. “I figured maybe I sat on my phone weird, or was accidentally pushing some button that was causing these, and so I just denied them all.”
Chris says the attackers persisted hitting his devices with the reset notifications for several days after that, and at one point he received a call on his iPhone that said it was from Apple support.
“I said I would call them back and hung up,” Chris said, demonstrating the proper response to such unbidden solicitations. “When I called back to the real Apple, they couldn’t say whether anyone had been in a support call with me just then. They just said Apple states very clearly that it will never initiate outbound calls to customers — unless the customer requests to be contacted.”

Massively freaking out that someone was trying to hijack his digital life, Chris said he changed his passwords and then went to an Apple store and bought a new iPhone. From there, he created a new Apple iCloud account using a brand new email address.
Chris said he then proceeded to get even more system alerts on his new iPhone and iCloud account — all the while still sitting at the local Apple Genius Bar.
Chris told KrebsOnSecurity his Genius Bar tech was mystified about the source of the alerts, but Chris said he suspects that whatever the phishers are abusing to rapidly generate these Apple system alerts requires knowing the phone number on file for the target’s Apple account. After all, that was the only aspect of Chris’s new iPhone and iCloud account that hadn’t changed.
WATCH OUT!
“Ken” is a security industry veteran who spoke on condition of anonymity. Ken said he first began receiving these unsolicited system alerts on his Apple devices earlier this year, but that he has not received any phony Apple support calls as others have reported.
“This recently happened to me in the middle of the night at 12:30 a.m.,” Ken said. “And even though I have my Apple watch set to remain quiet during the time I’m usually sleeping at night, it woke me up with one of these alerts. Thank god I didn’t press ‘Allow,’ which was the first option shown on my watch. I had to scroll watch the wheel to see and press the ‘Don’t Allow’ button.”

Ken shared this photo he took of an alert on his watch that woke him up at 12:30 a.m. Ken said he had to scroll on the watch face to see the “Don’t Allow” button.
Unnerved by the idea that he could have rolled over on his watch while sleeping and allowed criminals to take over his Apple account, Ken said he contacted the real Apple support and was eventually escalated to a senior Apple engineer. The engineer assured Ken that turning on an Apple Recovery Key for his account would stop the notifications once and for all.
A recovery key is an optional security feature that Apple says “helps improve the security of your Apple ID account.” It is a randomly generated 28-character code, and when you enable a recovery key it is supposed to disable Apple’s standard account recovery process. The thing is, enabling it is not a simple process, and if you ever lose that code in addition to all of your Apple devices you will be permanently locked out.
Ken said he enabled a recovery key for his account as instructed, but that it hasn’t stopped the unbidden system alerts from appearing on all of his devices every few days.
KrebsOnSecurity tested Ken’s experience, and can confirm that enabling a recovery key does nothing to stop a password reset prompt from being sent to associated Apple devices. Visiting Apple’s “forgot password” page — https://iforgot.apple.com — asks for an email address and for the visitor to solve a CAPTCHA.
After that, the page will display the last two digits of the phone number tied to the Apple account. Filling in the missing digits and hitting submit on that form will send a system alert, whether or not the user has enabled an Apple Recovery Key.
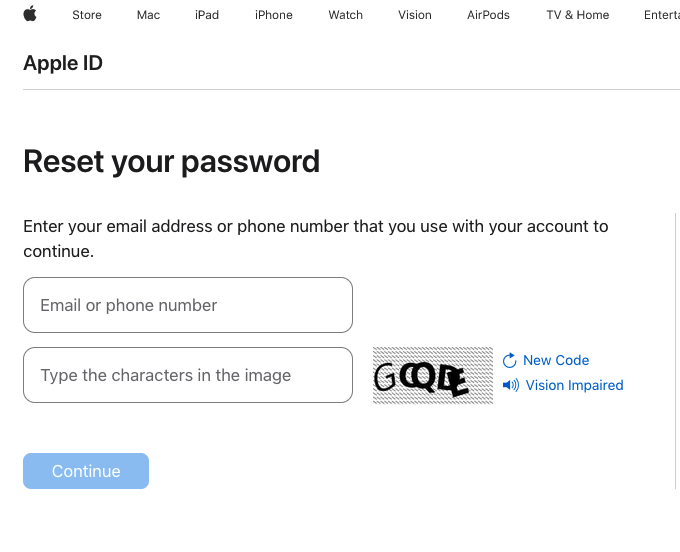
The password reset page at iforgot.apple.com.
RATE LIMITS
What sanely designed authentication system would send dozens of requests for a password change in the span of a few moments, when the first requests haven’t even been acted on by the user? Could this be the result of a bug in Apple’s systems?
Apple has not yet responded to requests for comment.
Throughout 2022, a criminal hacking group known as LAPSUS$ used MFA bombing to great effect in intrusions at Cisco, Microsoft and Uber. In response, Microsoft began enforcing “MFA number matching,” a feature that displays a series of numbers to a user attempting to log in with their credentials. These numbers must then be entered into the account owner’s Microsoft authenticator app on their mobile device to verify they are logging into the account.
Kishan Bagaria is a hobbyist security researcher and engineer who founded the website texts.com (now owned by Automattic), and he’s convinced Apple has a problem on its end. In August 2019, Bagaria reported to Apple a bug that allowed an exploit he dubbed “AirDoS” because it could be used to let an attacker infinitely spam all nearby iOS devices with a system-level prompt to share a file via AirDrop — a file-sharing capability built into Apple products.
Apple fixed that bug nearly four months later in December 2019, thanking Bagaria in the associated security bulletin. Bagaria said Apple’s fix was to add stricter rate limiting on AirDrop requests, and he suspects that someone has figured out a way to bypass Apple’s rate limit on how many of these password reset requests can be sent in a given timeframe.
“I think this could be a legit Apple rate limit bug that should be reported,” Bagaria said.
Adblock test (Why?)









